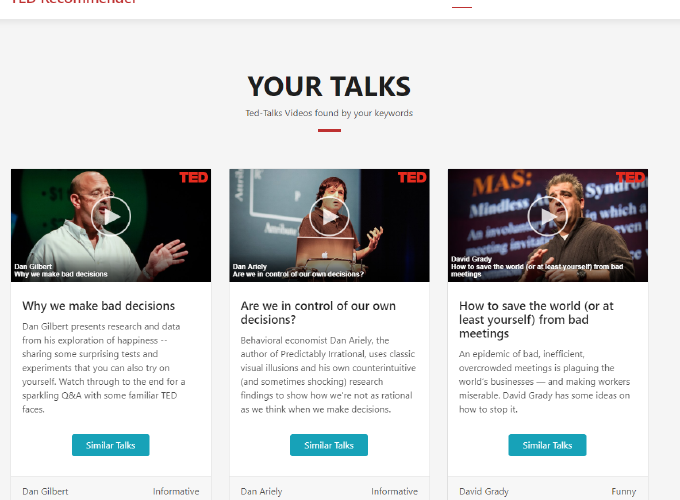
As data grow rapidly, we often get lost in what we want to find. For example, there is a lot of different items available on Amazon. It is impossible for us as customers to go and search for exactly what we want every time. Recommender system comes out handy to help items reach out to their clients easier. Whenever we search, purchase, or give feedback for an item, Amazon will immediately suggest similar items, which give us more selections.
To replicate a simple recommender system, we use a combination of content-based and collaborative filtering for our system. However, we need many different users to have diverted ratings on our system to implement collaborative filtering. As a simple system with a static dataset, it would be easier to just apply content-based for our recommender system.
1. Back-end Engine:
To construct a content-based recommend system, our mission is to build a profile for each ted-talk video. Each video profile consists of characteristics of terms that are important to the talks. For example, those features can be the title, author name, or category of the talk. Whenever users need a suggestion on a given video, we can use the video’s profile to look for the closet videos base on their Cosine Similarity.
Intuitively, characteristic features of each talk would be their title, author name, category, and description. Therefore, as the first step of preprocessing, we need to make sure we got all the needed column in our vocabulary.

The next step is to make sure we got all the important terms, but not repeated form, or unnecessary words. To complete this task we first tokenize all documents, eliminate words appear in stop words list from nltk library, and perform stemming to avoid words with different forms.

Since all remaining terms on each document are all considered important characteristics, we represent talks profile by all remaining term with their TF-IDF scores.

Whenever users request for a suggestion on a video, we capture the video ID from the front-end, send it to back-end and start looking for its characteristics. We should perform the same preprocessing steps on the given video. The final step is to look for the most similar videos based on their Cosine Similarity point and send it to front-end for representation.

2. Contribution:
All back-end logic and calculation are developed based on Chapter 9 Recommendation Systems of Mining of Massive Datasets book. However, the algorithm to complete this task is manually generated. Because even though we concatenated all characteristic terms of each video, the final terms in each document are not that very long. Therefore, it would be better to keep all the terms’ TF-IDF scores instead of just pick n terms as the features. Moreover, to make sure the author name is more important because it is a high chance that users want to watch more videos from the same author, I also put the author name inside of the talk’s titles.
3. Challenging:
As the same as other Bag of Words models, the recommend system only suggests videos based on the similarities between the occurrences of the same words, without any meaning behind the context.
In the beginning, I try to also keep the transcript, which is the context of the whole text, for computation. However, since we have to calculate all TF-IDF scores for every term inside the documents, the run time of the application becomes too long. Therefore, I have to downsize the computation pool to the title, author name, category, and description of the talks.
Reference:
TED-Talks videos on TED-Talks (https://www.kaggle.com/rounakbanik/ted-talks).
Chapter 9 Recommendation Systems, Mining of Massive Datasets by Jure Leskovec, Anand Rajaraman, Jeff Ullman