To implement a search feature, which is very similar to a simple version of google, the easiest way is to use Bag of Words model, to give a TF-IDF weight to each word appear in the dataset. Therefore, whenever you enter a query, the application would return the documents contains the query terms with the biggest total weight.
For the dataset of all videos on TED-Talks (https://www.kaggle.com/rounakbanik/ted-talks), the mission is to construct a postings list for all the terms in video title, author, description, and script columns. Each term in the postings list would have the form of term t: [document d1, TF-IDF weight w1], [document d2, TF-IDF weight w2], …
1. Back-end Engine:
To complete the task, I use python 3.6 for the back-end, and refer to the instructions of Dr. Chengkai Li in his Data Mining class (http://crystal.uta.edu/~cli/cse5334/).
Preprocessing:
First of all, we need to read the data inside the csv file. We can archive this easily by using pandas library.
 |
With just one simple line of code, we now retrieve all the csv file in tedData, which can be used to read all the data in each column separately. The next step is to go to all the columns that contain the context we need such as title, description, speaker name, and script. Now, what we need is to tokenize all of this context into separate terms using RegexpTokenizer, then store all the terms in one big giant array.
 |
So now we have one big array of all the terms in each document. The problem is there are many terms that are not so important to consider, because they are used many times in every document such as pronouns, to-be verbs, or prepositions. We can eliminate all these terms by import a stop words lists from nltk library, and remove words appear in the list.
Moreover, in English, one words usually have many different forms such as tenses or plural. So, we also need to perform stemming to shorten these words and treat them as the same. After these 2 steps, we cut down a big size of memory to store all the terms.
 |
Processing:
The mission of processing is to go through the Bag of Words to give each word their lists of documents and corresponding TF-IDF weight in the form of term t: [document d1, TF-IDF weight w1], [document d2, TF-IDF weight w2], …
To complete this task, first, we create weight vectors, which is dictionary variables with each term as a key. For each document, we pick up the key term t, calculate their weight w for the document d and store it as a value. The TF-IDF of the term for each document would be given by:

Where tf is term frequency, which is measure by how many times the term occurs in the document.
df is document frequency, which is the count of how many documents contain the term.
N is the total number of documents.
 |
When we already had an array of weight vectors, the next step is to construct a postings list for each term. For each term, that appears in the dataset, we give them all of their documents and corresponding weights as value. Moreover, do not forget to sort the lists by their weight to always consider the most related documents first.
 |
Search:
For each search, we are given a query by user. The first thing to do is to give each term appear in the query a weight, which is equal their occurrences in the query divide by the length of the query:

Each term in the query will then be given total similarity points respect to the documents, that each term appears:

Where Wt,q is the weight of the term in the query.
Wt,d is the weight of the term in the document.
The final step is to sort the similarity list, so that, we can retrieve the most related documents.
 |
Contribution:
Combine the tutorial by Dr. Chengkai Li with the computation theory from the book Introduction to Information Retrieval. Since the formula for calculating similarity in the book is theory, that is explained using mathematical representation, I construct the algorithm from scratch. Because there are a lot of computations of TF-IDF weight, the process would take hours, or days to be completed. I have successfully performed preprocessing to reconstruct the dataset, eliminate space characters, stop-list words, and shorten all the terms to downsize and fasten the processing time significantly.
2. App Framework:
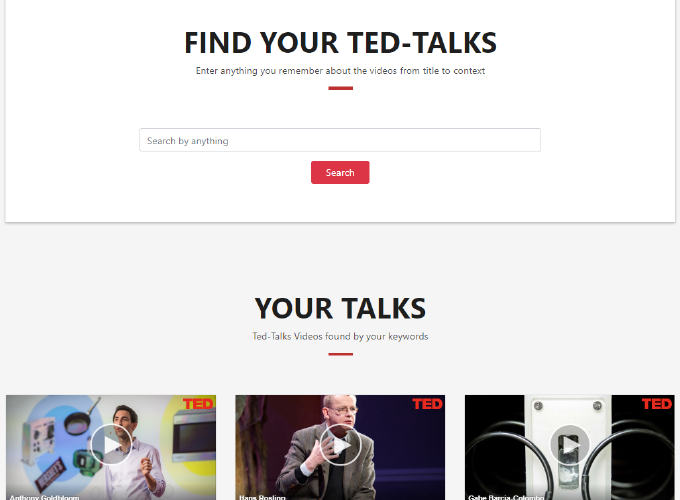
After processing the data, we now can search for TED-Talks videos by give the application a query. However, we need a complete application with User Interface to be able to do search. For this purpose, I use Flask as the framework to connect my back-end engine to a web application because of its simplicity for a small application.
The first thing we need to do is to import flask library as any other libraries and initiate our back-end engine.
When users enter the web application URL, we can simply use app.route(“/”) function to direct them to our index homepage, and give the homepage our ted-data.
 |
Because this application would use only one single web page. Users can use search directly from the homepage and give server a POST request. The server will then perform search and return the most six related results back to the homepage. The front end will then render the results as videos using the returned links to the users.
 |
3.Front-End:
Because this is a simple application for research purpose, we can use very simple html page with a single text input and return related TED-Talks titles by text. However, we can create a simple good-looking web page using free bootstrap template on (https://startbootstrap.com/). With pure Html, and CSS we can modify the template to fit our purpose of the application.
4.Hosting:
Hosting should not be a problem when there are many platforms that we can use such as Pythonanywhere, Heroku, or Amazon AWS. For this application I use a free credit trial account on Digital Ocean, which give me a very strong CPU and a very friendly user interface to interact with.

When connected to the host terminal, we can run the application as we run it on local by run the ted.py file, which contain our main function and flask app.

Just remember to let the app run on host 0.0.0.0 and port 80, so that we can retrieve the web application by connecting to the floating IP of the hosting machine. For example, you can request TED Recommender web page by the URL: http://3.17.150.50
 |
6. Challenging:
Because the search feature use Bag of Words model, the engine just collects all the words and calculate their weights without understanding any of the term’s semantics. Therefore, the application can only return the documents that contains most of the terms in the query. If users enter a query using any other meaning of the term, the application might not return user’s expected documents.
Moreover, the application breaks the query into terms and treat them separately. So, if users enter a sequence of terms, such as titles of the talks, the TED-Talk with the expected title would have lower priority than other videos that contains the terms in the query with more occurrences.
In developing the application, the most challenging part is the run time. Because the algorithm has to go through all the script of each video, which is very long and contains big size of words. Tokenize and compute TF-IDF weight of every word cost a lot of run time. For the ted.py file to complete the process and got the web application running, it usually takes 5 to 10 hours to finish. Therefore, for each time I need to test the engine, I must down size the preprocessing step to only tokenize the title of the videos.
Reference:
TED-Talks videos on TED-Talks (https://www.kaggle.com/rounakbanik/ted-talks).
Chapter 6 Scoring, term weighting and the vector space model, Introduction to Information Retrieval by Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze
Dr. Chengkai Li Data Mining class (http://crystal.uta.edu/~cli/cse5334/).