In the real world, data usually divided into different categories or genres. For example, movies would have action, horror, comedy, or family as genres. However, what if we have already had all the movies manually categorized, and we want to classify a new movie? This actually can be done using very simple concept of probability, which is Naïve Bayes.
Refer to our data set of TED-Talks videos on TED-Talks (https://www.kaggle.com/rounakbanik/ted-talks), we can calculate the conditional probability of each term in the data set’s vocabulary appear in each category. For example, we would want to know what’s the conditional probability of the term “laugh” appears in “Funny” videos.
The classification is implemented on top of the TED-Recommender Web Application. Therefore, all the App Framework, Presentation, and Hosting would be the same and can be refer at the last post: Implement TF-IDF weight for search(https://tungpv.com/post/how-to-search/).
1. Preprocessing:
Because the data set ratings column consists of many categories for one video, the first step we have to do is to pick only one category and limited the number of categories.

For research purpose, and for faster processing time, I will only choose 10 categories to consider. Therefore, for each video, I would pick the most vote category, and if the ratings ID is bigger than 10, I would eliminate it and pick the next one.

After saving the new data set, we can perform RegexpTokenizer, Stemming, and eliminate stop words on the data set to construct a full vocabulary list (Refer this important step for preprocessing to last post: https://tungpv.com/post/how-to-search/).
2. Processing:
The whole process for classification would be implement using the concept of Naïve Bayes.

Therefore,the mission is to construct a table to store the conditional probability for each term in the
vocabulary respect to each category.
However, first, for each class c in the categories, the prior probability would be the number of documents in class c divide by the total number of documents.

Then the conditional probability can be calculated by the frequency of term t in documents belong to class c.

However, to avoid sparseness that would lead conditional probabilities to be zero, we should apply smoothing into the calculation. To do this, we add 1 to all the term to avoid 0 on the numerator and add the number of unique terms to the denominator for normalization.

To implemented all the calculation into our Ted Engine, I run a loop to compute all the condition probability of each term in the respected class.

3. Classification:
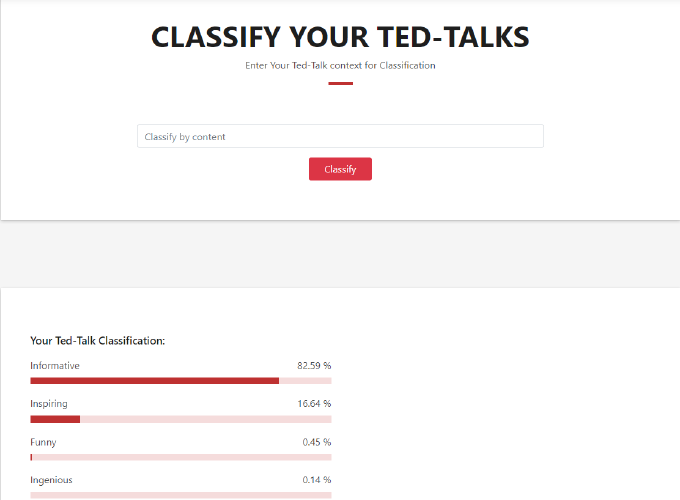
Whenever a query is given for classification, they would go through the same preprocessing of Tokenization, Stemming, and eliminate Stop Words. Next step, a score will be given for each class using Naïve Bayes. The final step is to sort the score and send it to the front-end for presentation.

4. Contribution:
Although the whole concept and computation are developed based on the Text classification and Naïve Bayes on Introduction to Information Retrieval, the algorithms are built manually to fit the application purpose and dataset structure. The computations are fully constructed from theorem, mathematical representation to code. Modify the formula for calculating the probability to not only classify the document to the most probability class, but also show all other percentages of classes for evaluations.
5. Challenging:
The classification function use a very simple concept of Naïve Bayes. However, because there are assumptions about the relations of the condition probabilities, the classification score can be incorrect. The conditional probabilities can eventually become zero when the query getting too long due to many multiplications of very small number. We can solve this by compute the score base on the sum of log between conditional probabilities, which is much more reliable and scalable. Moreover, because the vocabulary is very large, the computational time is very long, even though the categories size has already been reduced a lot.
Reference:
TED-Talks videos on TED-Talks (https://www.kaggle.com/rounakbanik/ted-talks).
Text classification and Naïve Bayes (https://nlp.stanford.edu/IR-book/pdf/13bayes.pdf).